Data Collection
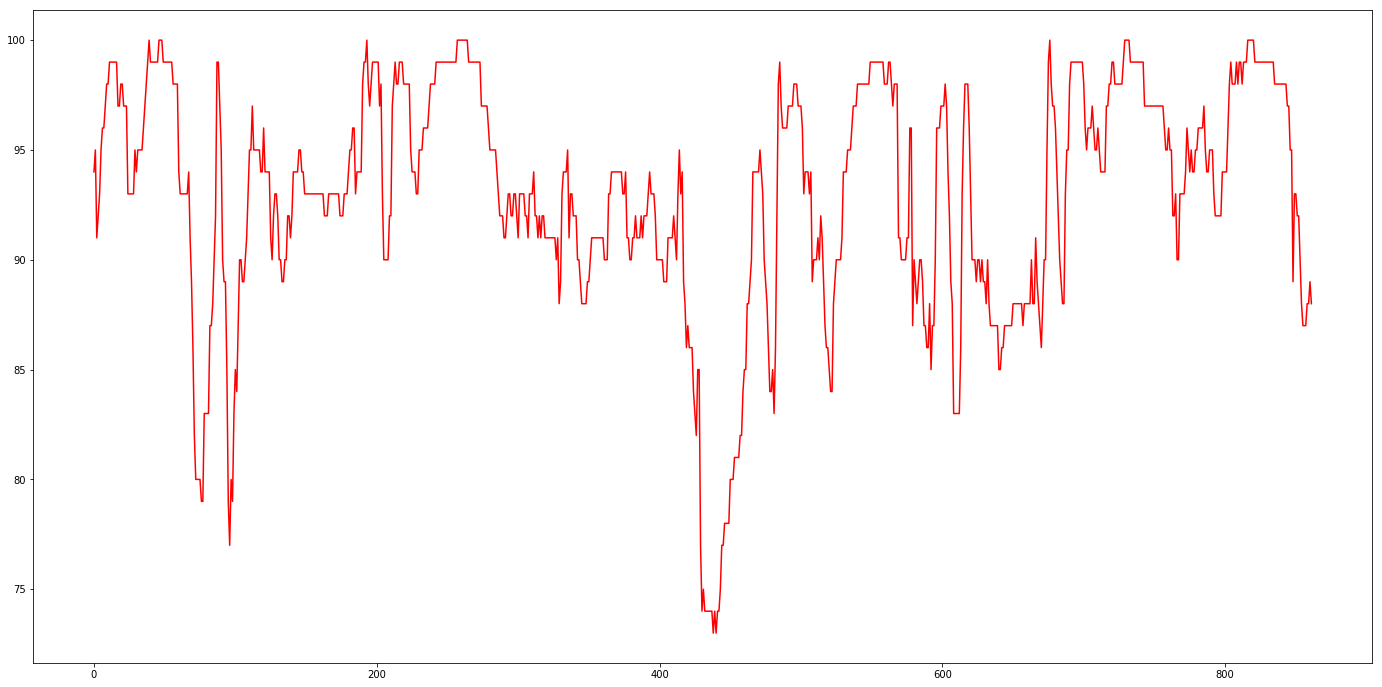
Data was collected for ~9 days, July 5, 8:45am through July 14, 10:15am. Data was sampled using the Twitter Search API once every 15 minutes, 96 samples per day, 863 total samples. Each sample requested the maximum number of tweets allowed for free which is 100 tweets. Some samples fell short of this maximum (see figure for Tweet Counts Per Sample). Tweet data was saved as text files in json format.
The Problem of Duplicate Tweets
All datasets to this point have been known to include duplicate tweets but this dataset is the most extreme yet. Out of 85770 total tweets, there are only 6255 unique tweets and only 4877 unique users. This is forcing me to investigate why I am getting so many duplicates. I am using the TwitterAPIExchange.php library. They provide a simple example of using the search API to search for #nerd which I am currently testing. So far there appears to be duplicates in each 15 minute sample.
The resulting visualizations which include duplicate tweets show a much more complex and exotic structure. This is due to a difference in the sorting order of the top tweeters since the tweet/retweet count is different when I exclude duplicates. Why the sorting order takes on this kind of appearance is still difficult to understand, and even though there is a difference, the sorting order may remain somewhat similar between the two different datasets.
It is difficult to understand why I am getting so many duplicates. A google search indicates there was a known problem some time during mid-March 2018 which was apparently short-term and ultimately resolved.
I cannot find any indication of a general problem or a Twitter policy with these limits by default. My search query is maybe too complex, so I simplified it to "#nerd' and ran a basic test. So far, out of 97 total tweets, only 68 are unique, thus there are duplicates. There are roughly 12-14 tweets per sample by default. Next, I added the filter "count=180" as I have been doing in all of my prior searchers in order to max out the number of tweets per sample. This resulted in up to but not exceeding 100 tweets per sample.
I will also try an alternative API library such as Python to do the capture.
Time vs. Top Tweeters, Unique vs. Duplicate Tweets
Download ANTz visualization of time vs. top tweeters including duplicate tweets for Windows.
Download ANTz visualization of time vs. top tweeters including unique tweets for Windows.
Numerous gaps are prominent which appear to narrow as we approach the top tweeters.
There were 4877 unique users.
Legend

Top Tweeters vs. Time, Including Duplicate Tweets
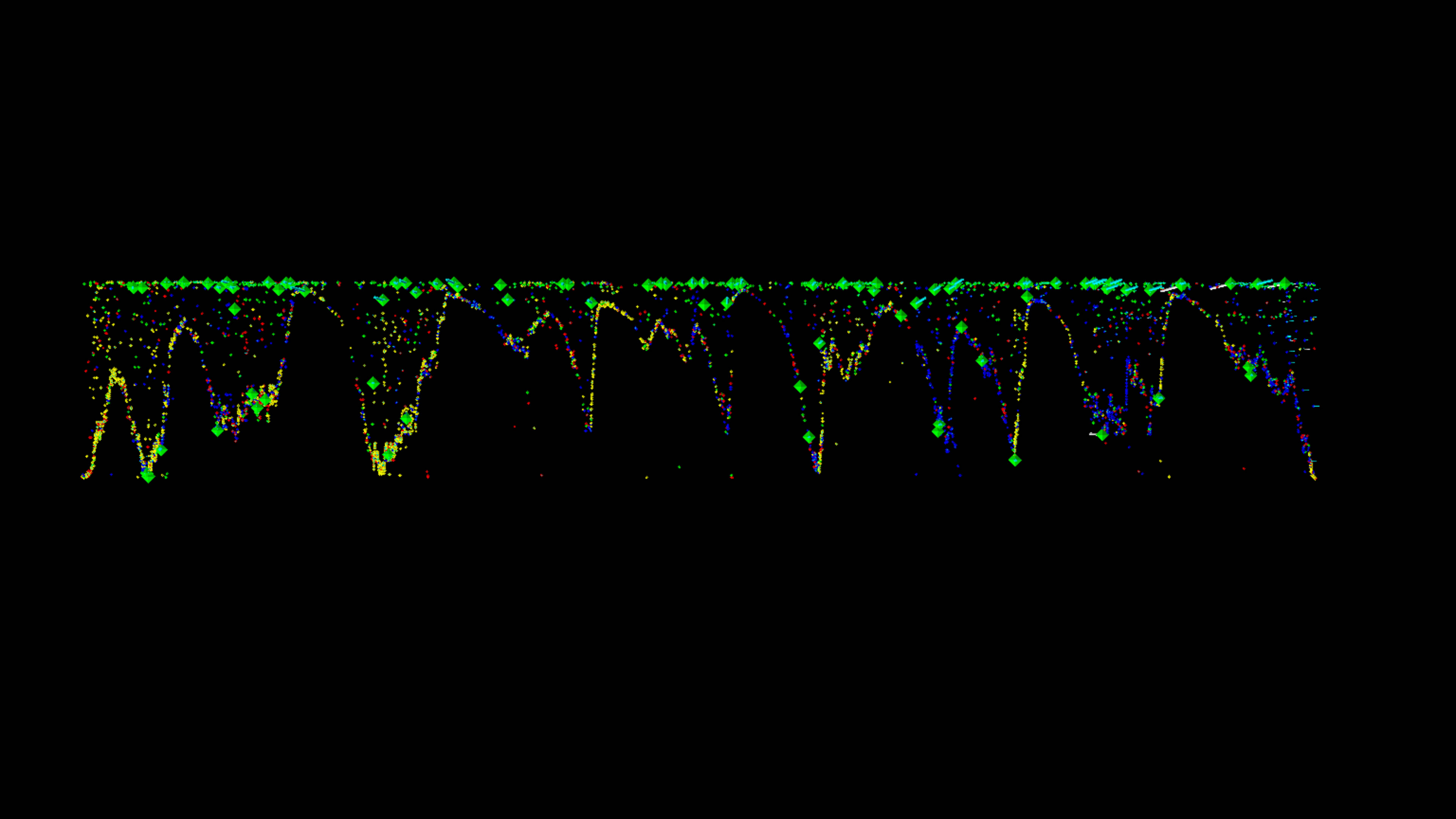
Top Tweeters vs. Time, Only UniqueTweets

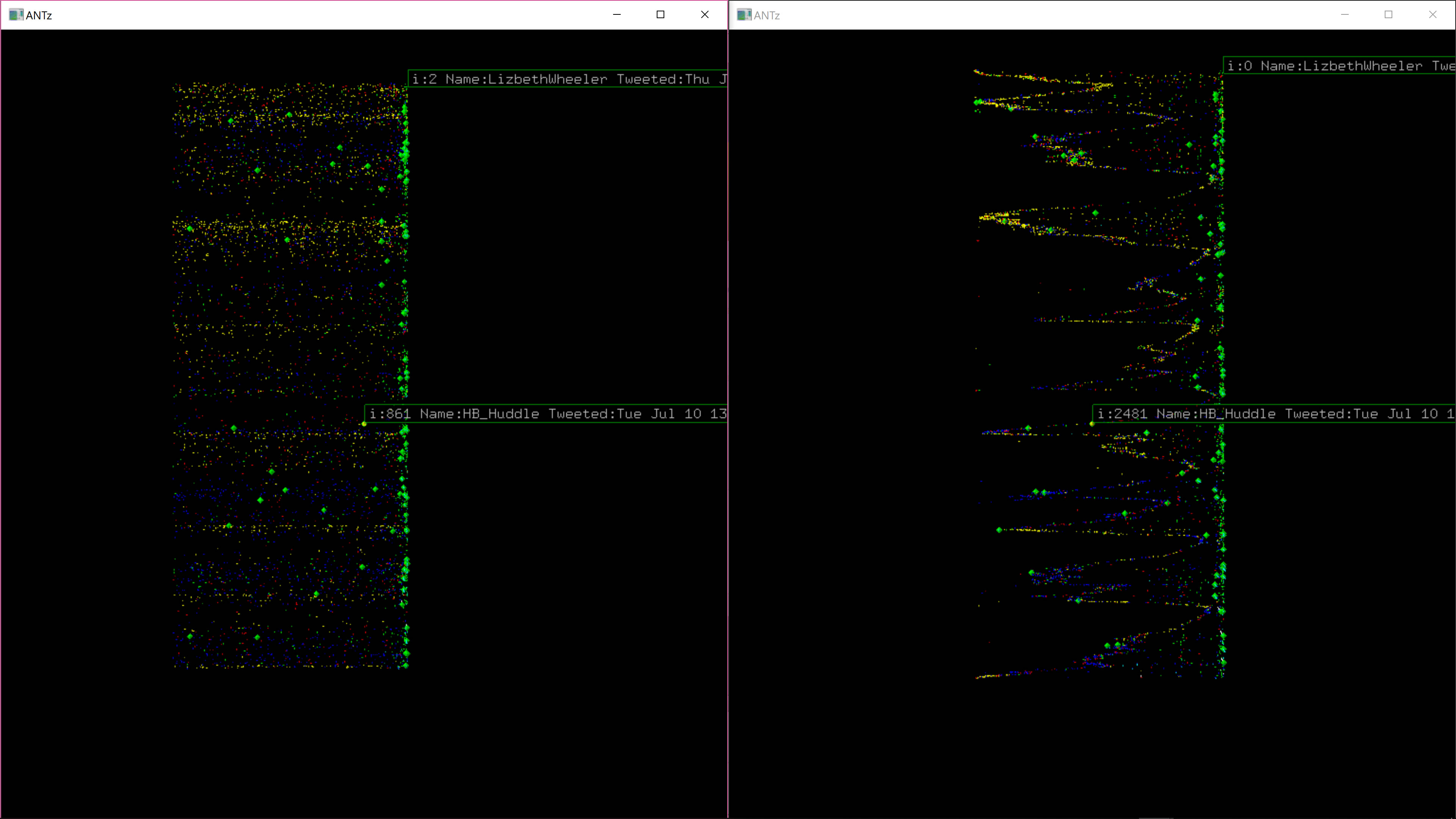
Side-by-Side Comparison of Unique vs. Duplicate
Unique Tweets, Perspective
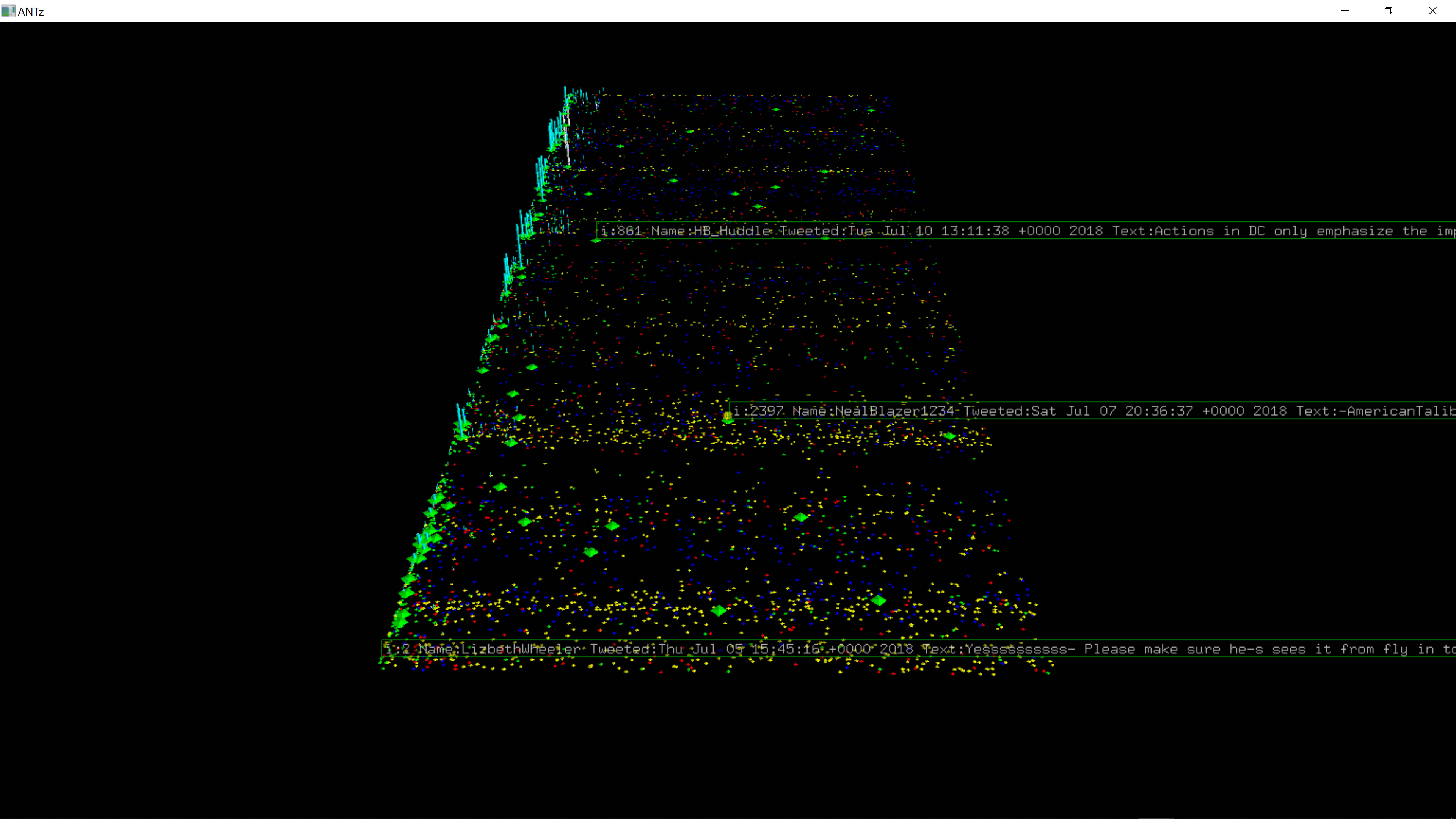
Duplicate Tweets, Perspective
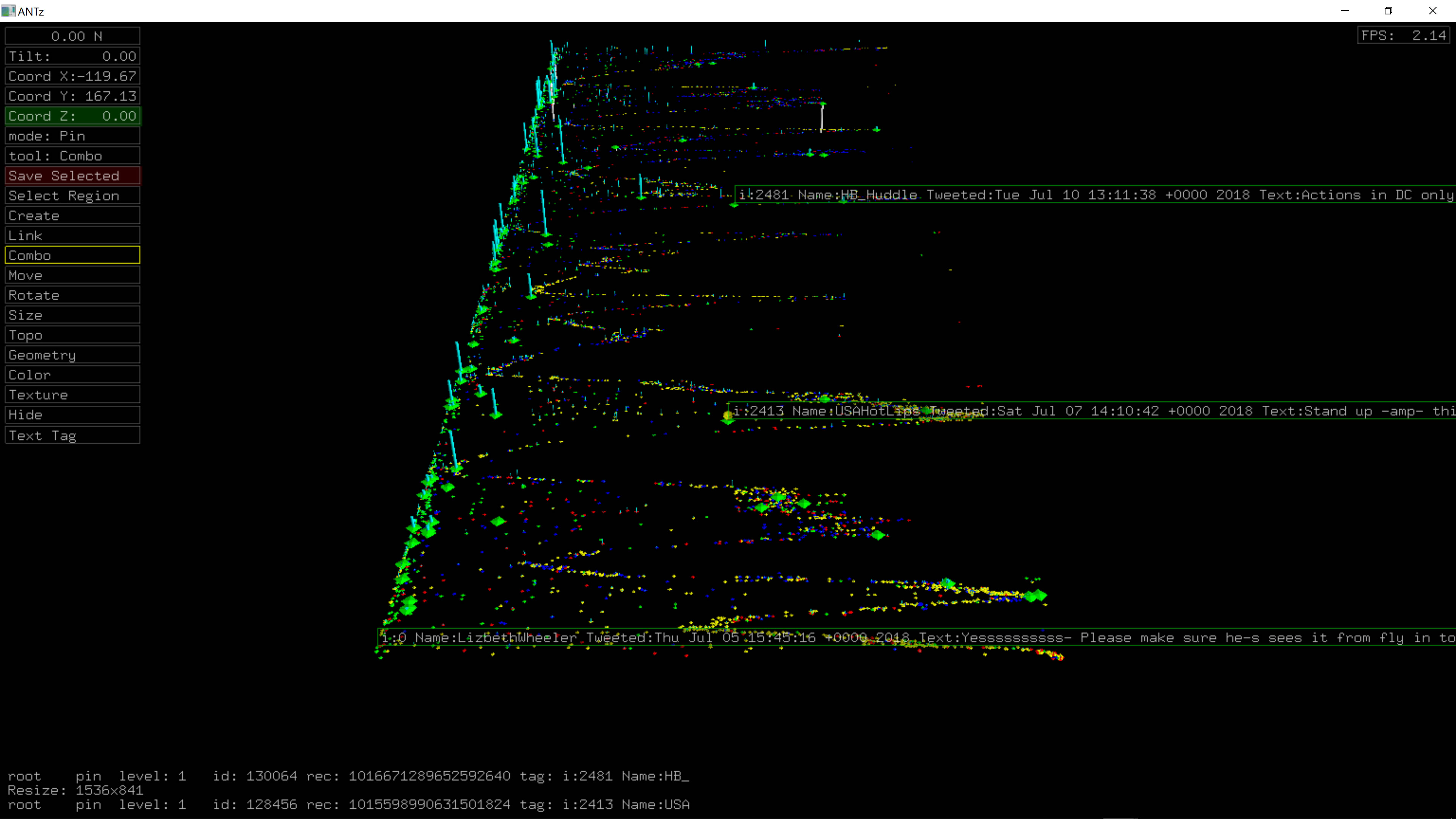
Tweet Counts Per Sample
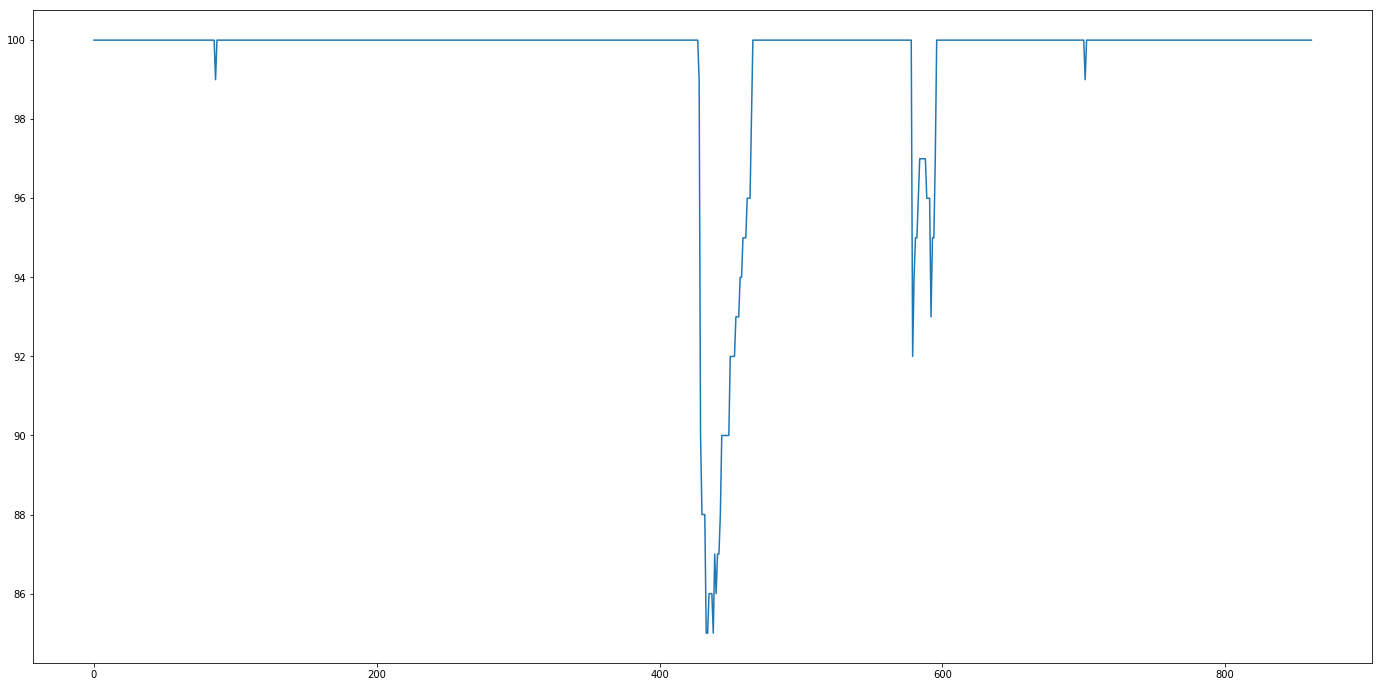
Distinct User Names Per Sample